2010. 5. 26. 18:36ㆍC++
TCHAR, _tmain, wmain이 뭘까?
일단 질문에 답하기 전 알아두어야 할 것들을 살펴보면...
문자 코드
아스키코드(ASCII CODE)
- 미국에서 정의한 문자셋 표준
- 알파벳 26개와 몇몇 확장 문자를 포함해 256개를 넘지 않아 1바이트로 표현
유니코드 (UNICODE)
- 영어가 아닌 다른 국가 문자들은 아스키코드 1바이트로 모두 표현하는데 부족하다.
- 따라서 2바이트를 유니코드라는 것이 등장, 나타낼 수 있는 문자의 종류도 65,535개에 이르게 된다.
문자셋 표현 방법에 따라 C 프로그래밍
[SBCS(Sinble Byte Character Set)]
- 문자를 표현하는데 있어서 1바이트만을 사용
- 아스키코드 기반의 문자열
[MBCS(Multi Byte Character Set)]
- 문자를 표현하는데 있어서 다양한 바이트 수를 사용해 문자를 표현하는 방식
- 영어는 1바이트로, 한글은 2바이트로 처리
|
#include <stdio.h>
int main(void) { char str[] = "ABC한글"; // 아스키코드 "ABC"와 유니코드 "한글"을 동시에 저장 (크기를 찍으면 NULL문자까지 포함) int i; int size = sizeof(str); int len = strlen(str);
printf("배열의 크기: %d\n", size); printf("문자열의 길이: %d\n", len);
for(i=0; i<5; i++) fputc(str[i], stdout);
for(i=0; i<7; i++) fputc(str[i], stdout);
return 0; } |
- 실행 결과
|
배열의 크기: 8 문자열의 길이: 7 ABC한 ABC한글 |
- MBCS의 문제점
예제코드의 실행결과를 보면 글자는 분명히 'A', 'B', 'C', '한', '글' 이렇게 5글자 인데 for문을 5번돌려도 글자 5개가 다 출력되지 않
는다. (다 출력하려면 for문을 7번 돌려야하는 상황 발생)
[WBCS(Wide Byte Character Set)]
- 모든 문자를 2바이트로 처리하는 문자셋
- 유니코드 기반 문자열
|
#include <stdio.h>
int wmain(int argc, wchar_t* argv[]) { wchar_t str[] = L"ABC"; // 유니코드 (크기를 찍으면 NULL문자까지 포함) int size = sizeof(str); int len = wcslen(str);
wprintf(L"배열의 크기: %d\n", size); wprintf(L"문자열의 길이: %d\n", len);
for(int i=1; i<argc; i++) { fputws(argv[i], stdout); fputws(L"\n", stdout); }
return 0; } |
- 실행 결과
|
배열의 크기: 8 문자열의 길이: 3 AAA BBB CCC |
- WBCS의 문제점
예제코드 상에는 문제가 없지만 만약 유니코드가 지원이 되지 않는 경우에 WBCS 기반으로 하면 어떻게 할 것인가?
MBCS와 WBCS의 Windows 스타일 자료형
|
#define CONST const
typedef char CHAR; typedef CHAR * LPSTR; typedef CONST CHAR * LPCSTR;
typedef wchar_t WCHAR; typedef WCHAR * LPWSTR; typedef CONST WCHAR * LPCWSTR;
자세한 것은 windows.h 참조 (매크로 CONST는 windef.h에, 나머지는 winnt,h에 정의) |
프로그래밍 할 때마다 MBCS, WBCS 둘 중 하나의 기반으로 정해서 프로그래밍 하기엔 좀 번거롭다. WBCS 기반으로만 한다고 할 경우 현존하는 모든 시스템이 완벽히 유니코드 기반을 지원하지 않는 경우엔 어떻게 할 것인가? MBCS도 아까 봤던 문제점이 도사리고 있다. 따라서 MBCS와 WBCS를 동시 지원하는 좋은 방법이있다. 이게 본론인데 이거 쓰려고 서두가 길었다. -_-;;
MBCS와 WBCS(유니코드)를 동시에 지원하기 위한 매크로
|
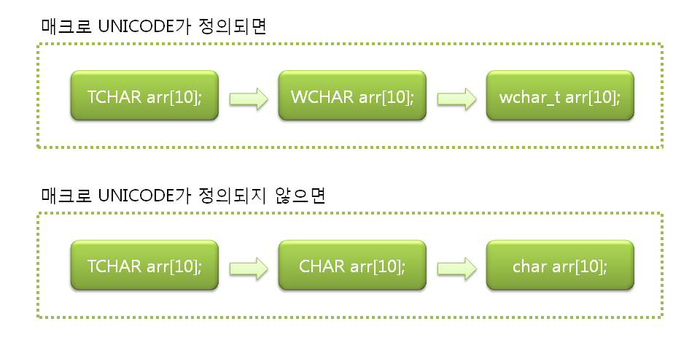
#ifdef UNICODE typedef WCHAR TCHAR; typedef LPWSTR LPTSTR; typedef LPCWSTR LPCSTR; #else typedef CHAR TCHAR; typedef LPSTR LPTSTR; typedef LPCSTR LPCSTR; #endif 자세한 것은 windows.h 참조 |
예제)
|
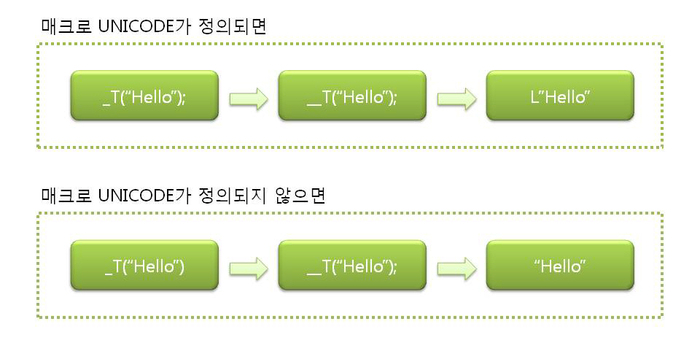
#ifdef _UNICODE #define __T(x) L ## x // L과 x를 결합 #else #define __T(x) x #endif
#define _T(x) __T(x) #define _TEXT(x) __T(x) 자세한 것은 tchar.h 참조 |
예제)
|
#ifdef _UNICODE #define _tmain wmain #define _tcslen wcslen #define _tcscat wcscat #define _tcscpy wcscpy #define _tcsncpy wcsncpy #define _tcscmp wcscmp #define _tcsncmp wcsncmp #define _tprintf wprintf #define _tscanf wscanf #define _fgetts fgetws #define _fputts fputws #else #define _tmain main #define _tcslen strlen #define _tcscat strcat #define _tcscpy strcpy #define _tcsncpy strncpy #define _tcscmp strcmp #define _tcsncmp strncmp #define _tprintf printf #define _tscanf scanf #define _fgetts fgets #define _fputts fputs #endif 자세한 것은 tchar.h 참조 |
예제)
|
#define UNICODE #define _UNICODE
#include <stdio.h> #include <tchar.h> #include <windows.h>
int _tmain(int argc, TCHAR* argv[]) { LPTSTR str1 = _T("MBCS or WBCS 1"); TCHAR str2[] = _T("MBCS or WBCS 2"); TCHAR str3[100]; TCHAR str4[50];
LPTSTR pStr = str1;
_tprintf( _T("string size: %d\n"), sizeof(str2) ); _tprintf( _T("string length: %d\n"), _tcslen(pstr) );
_tputts( _T("Input String 1 : "), stdout ); _tscanf( _T("%s"), str3 ); _tputts( _T("Input String 1 : "), stdout ); _tscanf( _T("%s"), str4 );
_tcscat(str3, str4); _tprintf( _T("String1 + String2 : %s \n"), sizeof(str3) );
return 0; } |