프로그래머십니까? Unicode,ASCII, UTF-8, euc-kr 이게 몰까요?
2007. 12. 18. 09:15ㆍJava
* 이글은 조엘온소프트웨에서 유니코드와 문자집합에 대한 고찰이 나오길래 좀더 분석해서 써봐야겠다는
생각이 들어서 작성하였습니다. ^^
프로그래밍을 하면서 제일 많이 겪는게 글자가 깨지는 거다.
2byte 문자를 쓰는 한글의 비애일까.
1. ASCII 코드
다음은 잘못된 것입니다.
"일반 텍스트는 ASCII 이며 8비트 문자열이다."
이건 영어권이나 가능하다. 무수히 많은 조합이 필요한 한글일경우 , 1byte로 문자를 표현하는 것은 불가능하다. 웃긴일이지 ㅡ.ㅡ; 개늠들.
다음은 1byte로 표현하는 ASCII 코드 표이다.
아주 영어만 쓰라고 이렇게 만들어 놨다. 보면 0~127, 글자는 32~127로 표현한다.
1byte는 -127~127 까지 총 2의 8승, 256개 이니 1byte로 된다. 물론 영어만.
2의 보수면 0~255까지, 총 7비트로 표현 가능하니 마지막 비트는 다른나라 사람들이 알아서 써라
이얘긴가보다. 이 영어 문자를 제외하고 나머지 128~255를 맵핑하면서 문제는 시작된다.
예를들어서, 미국에서의 pc는 128~255 bit값에 대한 맵핑과 이스라엘의 pc의 맵핑이 틀리면
메일을 보내면 resume => ?????? 같이 보여지게 될 것이다.
즉, 서로 제각각으로 이 1bit를 사용했다는 것임.
이런문제점을 통합해서 표준화 한것이 ANSI 이다. 128~256을 어떻게 사용할껀지에 대한 규약이다.
즉 이스라엘은 ANSI-862를 쓰고, 우리나라는 ANSI-949, 영어는 ANSI-437을 쓴다.
즉 코드페이지란 개념으로
코드페이지 949번은 128~255를 한글로 맵핑했다. 한글을 사용하는 사람들은 949로 맵핑해서 써라
이뜻이다.
윈도우에서는 chcp로 코드페이지를 변경할수 있단다.
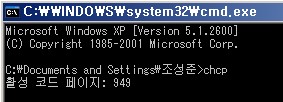
chcp를 치니깐 949를 쓴다고 나온다.
==================================================================================
2. 유니코드
자아 다음은 아시아다.
아시아권의 글자(한글,일본어,중국어)는 1byte로는 택도 없다는것을 알죠?
그래서 나온게 DBCS 라네요
Dobule Bytes Character Set 즉 나머지 모자라는 문자는 두번째 byte에 저장해라 이얘기다. 욕나온다.
이제 유니코드다. 유니코드가 나옴으로써 위의 문제들이 모두 해결된 것이다. 물론 불만은 많다 ㅡ.ㅡ;
유니코드가 하나의 "문자"를 무조건 2bytes 표현한다고 생각은 오류다. 2bytes 면 2의 16이니 65536까지 표현 가능하네. 자바에서는 하나의 문자(char)를 4byte로 표시한다, 아 C++은 2byte로 처리한다.
유니코드에서 글자는 코드 포인트라는 단순히 이론적인 개념으로 사상한다.
즉 A가 0100 0001 1byte로 이렇게 표현되지만,
만약 폰트가 달라지면 어떻게 할까
A 와 a 와 이상한 a 등등 A를 의미하는 것은 같지만, 모두 다르다.
즉 관념적인 A 다.
즉 폰트가 달라져도, 유니코드 페이지 값은 동일하다.
윈도우에서 실행>charmap 을 치면 이게 나온다. 오오~
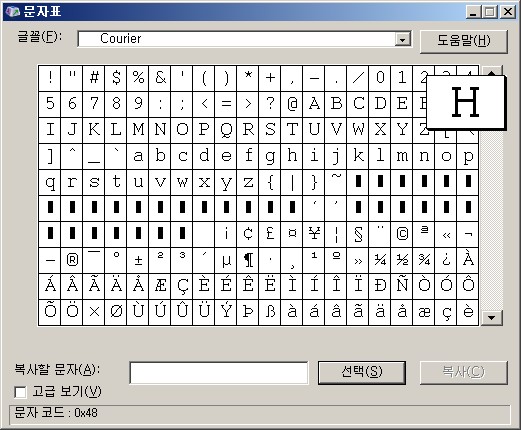
보면 H 를 선택했는데 문자코드가 0x48 이라고 나온다. 만약 폰트를 다른걸 선택해도 관념적인 H는 0x48 동일하다. 이런 관념적인 문자 코드 번호를 코드포인트라고 한다.
U+0048 이게 정확한 "H" 의 코드 포인트 인다.
이렇게 관념적으로 문자를 지정하니 폰트가 달라져도 모양만 바뀌게 되는것이다.
생각해보라. 우리가 사용하는 한글폰트들 얼마나 많은가. 그걸 몽땅 몇바이트에 넣어 사용한다면 ?
끔찍하다.
즉 H를 다른 폰트로 바꾸어도 코드포인트는 U+0048 동일하다.
여기서 문제가 있다. 이런 코드 포인트를 저장해야한다.
0048 이니 2byte에 저장하는 것이다.
즉 00(1byte), 48(1byte)
여기서 리틀 엔디안과 빅 엔디안의 개념이 나온다. 각 컴퓨터에서 좀더 빨리 돌리기 위해 이 순서를 바꾼것이다. 네떡하시는분들 아시죠?
* 리틀 엔디안과 빅 엔디안은 조나단 스위프트의 걸리버 여행기에 나오는 이야기로 삶은 달걀을 둥근쪽을 깨서 먹는 사람 Big Endian 과 뾰족한 쪽을 깨서 먹는 사람들 Little Endian 로 나누어 정치적 대립을 벌이는 소인국 이야기에서 유래 되었다.
즉 00 48 대신에 48 00 으로 쓰는 것이다. (리틀엔디안, 빅 엔디안)
그럼 이렇게 되면 무엇이 필요할까, 이 문자가 과연 리틀인지 빅인지 알아야 할꺼 아닌가
그래서 문자열 맨앞에 유니코드 바이트 순서표시를 붙였다. 그래야 서로 호환해서 바꾸던지 말던지 할꺼다.
3. UTF - 8
자아 여기서 문제다. 미국국적 즉 영어권 프로그래머들은 머가 불만일까
그들은 영어라(ㅡ.ㅡ;) 1byte면 표현 가능하다. 근데 매 문자 마다 2byte로 표현해야 하니 불만인거다. 저장공간 낭비라면서.. 아놔~
그래서 나온게 UTF-8 이다. UTF-8 은 0~127 사이에 존재하는 모든 코드 포인트들을 단일 바이트로 저장한다. 128이상인것은 2byte 째, 3byte째로 해서 최대 6byte 까지 확장해서 저장한단다. 이러면 기존 ASCII와 똑같이 맞아 떨어지니 굳이 바꿀필요 없다는 거다.
4. 인코딩
항상 이게 문제다. 왜 한글로 메일을 보냈는데, 받는쪽에서 깨져보일까.
=> 이건 보낼때 이 문자열이 어떤 인코딩방식인지 안알려줘서 그렇다.
(UTF-8, ASCII, ISO 8859-1(라틴), 윈도우1252(유럽) 도대체 어느것?)
이메일인경우 헤더에 "Content-Type: text/plain; charset="UTF-8" 같이 적어주면 된다.
HTML도 마찬가지다.
(근데 우낀게 태그선언을 안해도 한글로 보인다. 왜냐면, 윈도우가 자주쓰는 빈도를 파악해서 인코딩 해준단다.)
* 모든 문자를 표기하려면 UTF-8 을 써라. euc-kr로 표현 불가능한 문자 많다.
* euc-kr이나 ksc5601는 서로 같은 의미이다.
by ncanis(조성준)
생각이 들어서 작성하였습니다. ^^
프로그래밍을 하면서 제일 많이 겪는게 글자가 깨지는 거다.
2byte 문자를 쓰는 한글의 비애일까.
1. ASCII 코드
다음은 잘못된 것입니다.
"일반 텍스트는 ASCII 이며 8비트 문자열이다."
이건 영어권이나 가능하다. 무수히 많은 조합이 필요한 한글일경우 , 1byte로 문자를 표현하는 것은 불가능하다. 웃긴일이지 ㅡ.ㅡ; 개늠들.
다음은 1byte로 표현하는 ASCII 코드 표이다.
아주 영어만 쓰라고 이렇게 만들어 놨다. 보면 0~127, 글자는 32~127로 표현한다.
1byte는 -127~127 까지 총 2의 8승, 256개 이니 1byte로 된다. 물론 영어만.
2의 보수면 0~255까지, 총 7비트로 표현 가능하니 마지막 비트는 다른나라 사람들이 알아서 써라
이얘긴가보다. 이 영어 문자를 제외하고 나머지 128~255를 맵핑하면서 문제는 시작된다.
|
10진수 |
16진수 |
문자 |
의미 |
10진수 |
16진수 |
문자 |
|
0 |
0×00 |
NULL |
|
64 |
0×40 |
@ |
|
1 |
0×01 |
SOH |
start of heading |
65 |
0×41 |
A |
|
2 |
0×02 |
STX |
start of text |
66 |
0×42 |
B |
|
3 |
0×03 |
ETX |
end of text |
67 |
0×43 |
C |
|
4 |
0×04 |
EOT |
end of transmission |
68 |
0×44 |
D |
|
5 |
0×05 |
ENQ |
enquiry |
69 |
0×45 |
E |
|
6 |
0×06 |
ACK |
acknowledge |
70 |
0×46 |
F |
|
7 |
0×07 |
BEL |
bell |
71 |
0×47 |
G |
|
8 |
0×08 |
BS |
backspace |
72 |
0×48 |
H |
|
9 |
0×09 |
HT |
horizontal tab |
73 |
0×49 |
I |
|
10 |
0×0A |
LF |
NL line feed, new line |
74 |
0×4A |
J |
|
11 |
0×0B |
VT |
vertical tab |
75 |
0×4B |
K |
|
12 |
0×0C |
FF |
NP form feed, new page |
76 |
0×4C |
L |
|
13 |
0×0D |
CR |
carriage return |
77 |
0×4D |
M |
|
14 |
0×0E |
SO |
shift out |
78 |
0×4E |
N |
|
15 |
0×0F |
SI |
shift in |
79 |
0×4F |
O |
|
16 |
0×10 |
DLE |
data link escape |
80 |
0×50 |
P |
|
17 |
0×11 |
DC1 |
device control 1 |
81 |
0×51 |
Q |
|
18 |
0×12 |
DC2 |
device control 2 |
82 |
0×52 |
R |
|
19 |
0×13 |
DC3 |
device control 3 |
83 |
0×53 |
S |
|
20 |
0×14 |
DC4 |
device control 4 |
84 |
0×54 |
T |
|
21 |
0×15 |
NAK |
negative acknowledge |
85 |
0×55 |
U |
|
22 |
0×16 |
SYN |
synchronous idle |
86 |
0×56 |
V |
|
23 |
0×17 |
ETB |
end of trans. block |
87 |
0×57 |
W |
|
24 |
0×18 |
CAN |
cancel |
88 |
0×58 |
X |
|
25 |
0×19 |
EM |
end of medium |
89 |
0×59 |
Y |
|
26 |
0×1A |
SUB |
substitute |
90 |
0×5A |
Z |
|
27 |
0×1B |
ESC |
escape |
91 |
0×5B |
[ |
|
28 |
0×1C |
FS |
file separator |
92 |
0×5C |
|
|
29 |
0×1D |
GS |
group separator |
93 |
0×5D |
] |
|
30 |
0×1E |
RS |
record separator |
94 |
0×5E |
^ |
|
31 |
0×1F |
US |
unit separator |
95 |
0×5F |
_ |
|
32 |
0×20 |
SP |
SPACE |
96 |
0×60 |
. |
|
33 |
0×21 |
! |
|
97 |
0×61 |
a |
|
34 |
0×22 |
" |
|
98 |
0×62 |
b |
|
35 |
0×23 |
# |
|
99 |
0×63 |
c |
|
36 |
0×24 |
$ |
|
100 |
0×64 |
d |
|
37 |
0×25 |
% |
|
101 |
0×65 |
e |
|
38 |
0×26 |
& |
|
102 |
0×66 |
f |
|
39 |
0×27 |
' |
|
103 |
0×67 |
g |
|
40 |
0×28 |
( |
|
104 |
0×68 |
h |
|
41 |
0×29 |
) |
|
105 |
0×69 |
i |
|
42 |
0×2A |
* |
|
106 |
0×6A |
j |
|
43 |
0×2B |
+ |
|
107 |
0×6B |
k |
|
44 |
0×2C |
' |
|
108 |
0×6C |
l |
|
45 |
0×2D |
- |
|
109 |
0×6D |
m |
|
46 |
0×2E |
. |
|
110 |
0×6E |
n |
|
47 |
0×2F |
/ |
|
111 |
0×6F |
o |
|
48 |
0×30 |
0 |
|
112 |
0×70 |
p |
|
49 |
0×31 |
1 |
|
113 |
0×71 |
q |
|
50 |
0×32 |
2 |
|
114 |
0×72 |
r |
|
51 |
0×33 |
3 |
|
115 |
0×73 |
s |
|
52 |
0×34 |
4 |
|
116 |
0×74 |
t |
|
53 |
0×35 |
5 |
|
117 |
0×75 |
u |
|
54 |
0×36 |
6 |
|
118 |
0×76 |
v |
|
55 |
0×37 |
7 |
|
119 |
0×77 |
w |
|
56 |
0×38 |
8 |
|
120 |
0×78 |
x |
|
57 |
0×39 |
9 |
|
121 |
0×79 |
y |
|
58 |
0×3A |
: |
|
122 |
0×7A |
z |
|
59 |
0×3B |
; |
|
123 |
0×7B |
{ |
|
60 |
0×3C |
< |
|
124 |
0×7C |
| |
|
61 |
0×3D |
= |
|
125 |
0×7D |
} |
|
62 |
0×3E |
> |
|
126 |
0×7E |
~ |
|
63 |
0×3F |
? |
|
127 |
0×7F |
DEL |
예를들어서, 미국에서의 pc는 128~255 bit값에 대한 맵핑과 이스라엘의 pc의 맵핑이 틀리면
메일을 보내면 resume => ?????? 같이 보여지게 될 것이다.
즉, 서로 제각각으로 이 1bit를 사용했다는 것임.
이런문제점을 통합해서 표준화 한것이 ANSI 이다. 128~256을 어떻게 사용할껀지에 대한 규약이다.
즉 이스라엘은 ANSI-862를 쓰고, 우리나라는 ANSI-949, 영어는 ANSI-437을 쓴다.
즉 코드페이지란 개념으로
코드페이지 949번은 128~255를 한글로 맵핑했다. 한글을 사용하는 사람들은 949로 맵핑해서 써라
이뜻이다.
윈도우에서는 chcp로 코드페이지를 변경할수 있단다.
chcp를 치니깐 949를 쓴다고 나온다.
==================================================================================
2. 유니코드
자아 다음은 아시아다.
아시아권의 글자(한글,일본어,중국어)는 1byte로는 택도 없다는것을 알죠?
그래서 나온게 DBCS 라네요
Dobule Bytes Character Set 즉 나머지 모자라는 문자는 두번째 byte에 저장해라 이얘기다. 욕나온다.
이제 유니코드다. 유니코드가 나옴으로써 위의 문제들이 모두 해결된 것이다. 물론 불만은 많다 ㅡ.ㅡ;
유니코드가 하나의 "문자"를 무조건 2bytes 표현한다고 생각은 오류다. 2bytes 면 2의 16이니 65536까지 표현 가능하네. 자바에서는 하나의 문자(char)를 4byte로 표시한다, 아 C++은 2byte로 처리한다.
유니코드에서 글자는 코드 포인트라는 단순히 이론적인 개념으로 사상한다.
즉 A가 0100 0001 1byte로 이렇게 표현되지만,
만약 폰트가 달라지면 어떻게 할까
A 와 a 와 이상한 a 등등 A를 의미하는 것은 같지만, 모두 다르다.
즉 관념적인 A 다.
즉 폰트가 달라져도, 유니코드 페이지 값은 동일하다.
윈도우에서 실행>charmap 을 치면 이게 나온다. 오오~
보면 H 를 선택했는데 문자코드가 0x48 이라고 나온다. 만약 폰트를 다른걸 선택해도 관념적인 H는 0x48 동일하다. 이런 관념적인 문자 코드 번호를 코드포인트라고 한다.
U+0048 이게 정확한 "H" 의 코드 포인트 인다.
이렇게 관념적으로 문자를 지정하니 폰트가 달라져도 모양만 바뀌게 되는것이다.
생각해보라. 우리가 사용하는 한글폰트들 얼마나 많은가. 그걸 몽땅 몇바이트에 넣어 사용한다면 ?
끔찍하다.
즉 H를 다른 폰트로 바꾸어도 코드포인트는 U+0048 동일하다.
여기서 문제가 있다. 이런 코드 포인트를 저장해야한다.
0048 이니 2byte에 저장하는 것이다.
즉 00(1byte), 48(1byte)
여기서 리틀 엔디안과 빅 엔디안의 개념이 나온다. 각 컴퓨터에서 좀더 빨리 돌리기 위해 이 순서를 바꾼것이다. 네떡하시는분들 아시죠?
* 리틀 엔디안과 빅 엔디안은 조나단 스위프트의 걸리버 여행기에 나오는 이야기로 삶은 달걀을 둥근쪽을 깨서 먹는 사람 Big Endian 과 뾰족한 쪽을 깨서 먹는 사람들 Little Endian 로 나누어 정치적 대립을 벌이는 소인국 이야기에서 유래 되었다.
즉 00 48 대신에 48 00 으로 쓰는 것이다. (리틀엔디안, 빅 엔디안)
그럼 이렇게 되면 무엇이 필요할까, 이 문자가 과연 리틀인지 빅인지 알아야 할꺼 아닌가
그래서 문자열 맨앞에 유니코드 바이트 순서표시를 붙였다. 그래야 서로 호환해서 바꾸던지 말던지 할꺼다.
3. UTF - 8
자아 여기서 문제다. 미국국적 즉 영어권 프로그래머들은 머가 불만일까
그들은 영어라(ㅡ.ㅡ;) 1byte면 표현 가능하다. 근데 매 문자 마다 2byte로 표현해야 하니 불만인거다. 저장공간 낭비라면서.. 아놔~
그래서 나온게 UTF-8 이다. UTF-8 은 0~127 사이에 존재하는 모든 코드 포인트들을 단일 바이트로 저장한다. 128이상인것은 2byte 째, 3byte째로 해서 최대 6byte 까지 확장해서 저장한단다. 이러면 기존 ASCII와 똑같이 맞아 떨어지니 굳이 바꿀필요 없다는 거다.
4. 인코딩
항상 이게 문제다. 왜 한글로 메일을 보냈는데, 받는쪽에서 깨져보일까.
=> 이건 보낼때 이 문자열이 어떤 인코딩방식인지 안알려줘서 그렇다.
(UTF-8, ASCII, ISO 8859-1(라틴), 윈도우1252(유럽) 도대체 어느것?)
이메일인경우 헤더에 "Content-Type: text/plain; charset="UTF-8" 같이 적어주면 된다.
HTML도 마찬가지다.
(근데 우낀게 태그선언을 안해도 한글로 보인다. 왜냐면, 윈도우가 자주쓰는 빈도를 파악해서 인코딩 해준단다.)
* 모든 문자를 표기하려면 UTF-8 을 써라. euc-kr로 표현 불가능한 문자 많다.
* euc-kr이나 ksc5601는 서로 같은 의미이다.
by ncanis(조성준)