2013. 10. 3. 21:22ㆍC++
STL - 알고리즘
http://www.hanb.co.kr/network/view.html?bi_id=1627
9.1 STL 알고리즘 분류
STL 알고리즘은 크게 네 가지로 분류 할 수 있습니다.
- 변경 불가 시퀀스 알고리즘
- 변경 가능 시퀀스 알고리즘
- 정렬 관련 알고리즘
- 범용 수치 알고리즘
변경 불가 시퀀스 알고리즘에는 find와 for_each 등이 있으며 대상 컨테이너의 내용을 변경하지 못합니다. 변경 가능 시퀀스 알고리즘으로는 copy, generate 등이 있으며 대상 컨테이너 내용을 변경합니다.
정렬 관련 알고리즘은 정렬이나 머지를 하는 알고리즘으로 sort와 merge 등이 있습니다.
범용 수치 알고리즘은 값을 계산하는 알고리즘으로 accumulate 등이 있습니다.
STL의 모든 알고리즘을 설명하기에는 많은 지면이 필요하므로 위에 소개한 알고리즘 카테고리 별로 자주 사용하는 알고리즘 중심으로 어떤 기능이 있으며 어떻게 사용하는지 설명하겠습니다.
9.2 조건자
알고리즘 중에는 함수를 파라미터로 받아들이는 것이 많습니다. 알고리즘에서 함수를 파라미터로 받아들이지 않거나 기본 함수 인자를 사용하며 알고리즘을 사용하는 컨테이너의 데이터는 기본 자료 형만을 사용할 수 있습니다. 유저 정의형 자료 형(struct, class)을 담는 컨테이너를 알고리즘에서 사용하기 위해서는 관련 함수를 만들어서 파라미터로 넘겨줘야 합니다.
알고리즘에 파라미터로 넘기는 함수는 보통 함수보다는 함수객체를 사용하는 편입니다.
9.3 변경 불가 시퀀스 알고리즘
9.3.1. find
컨테이너에 있는 데이터 중 원하는 것을 찾기 위해서는 find 알고리즘을 사용하면 됩니다.
참고로 알고리즘을 사용하려면 algorithm 헤더 파일을 추가해야 합니다.
#include < algorithm >
find의 원형
template<class InputIterator, class Type> InputIterator find( InputIterator _First, InputIterator _Last, const Type& _Val );
첫 번째 파라미터에 찾기를 시작할 반복자 위치, 두 번째 파라미터에 마지막 위치(반복자의 end()와 같이 이 위치의 바로 앞까지 검색함), 세 번째 파라미터에는 찾을 값을 넘깁니다.
find가 성공하면 데이터가 있는 위치를 가리키는 반복자를 반환하고, 실패하면 반복자의 end()를 반환합니다.
find 사용 방법
vector< int > ItemCodes; …….. // ItemCodes 컨테이너의 시작과 끝 사이에서 15를 찾는다. find( ItemCodes.begin(), ItemCodes.end(), 15 );
find를 사용하여 캐릭터의 아이템을 검색하는 예제 코드 입니다.
< 리스트 1. 캐릭터 아이템 검색 >
#include <algorithm>
#include <vector>
#include <iostream>
using namespace std;
int main()
{
vector< int > CharItems;
CharItems.push_back( 12 );
CharItems.push_back( 100 );
CharItems.push_back( 77 );
vector< int >::iterator FindIter;
// CharItems의 처음과 끝에서 12를 찾는다.
FindIter = find( CharItems.begin(), CharItems.end(), 12 );
if( FindIter != CharItems.end() )
{
cout << "CharItem 12를 찾았습니다." << endl;
}
else
{
cout << "CharItem 12는 없습니다" << endl;
}
// CharItems 두 번째와 끝에서12를 찾는다
// ++CharItems.begin()로 반복자를 한칸 이동 시켰습니다.
FindIter = find( ++CharItems.begin(), CharItems.end(), 12 );
if( FindIter != CharItems.end() )
{
cout << "CharItem 12를 찾았습니다." << endl;
}
else
{
cout << "CharItem 12는 없습니다" << endl;
}
return 0;
}
< 결과 > 
<리스트 1>에서는 vector 컨테이너를 대상으로 했지만 vector 이외의 list, deque도 같은 방식으로 사용합니다.
다만 map, set, hash_map의 연관 컨테이너는 해당 컨테이너의 멤버로 find()를 가지고 있으므로 알고리즘에 있는 find가 아닌 해당 멤버 find를 사용합니다.
9.3.2 find_if
find를 사용하면 컨테이너에 있는 데이터 중 찾기 원하는 것을 쉽게 찾을 수 있습니다. 그런데 find만으로는 많이 부족합니다. 이유는 find는 기본형만을 컨테이너에 저장하고 있을 때만 사용할 수 있습니다. 만약 유저 정의형을 저장하는 컨테이너는 find를 사용할 수 없습니다. 이럴 때는 9.2에서 짧게 설명한 조건자를 사용해야 합니다. 즉 조건자에 어떤 방식으로 찾을지 정의하고 알고리즘에서 이 조건자를 사용합니다.
find_if는 기본적으로 find와 같습니다. 다른 점은 조건자를 받아들인다는 것입니다.
find_if 원형
template<class InputIterator, class Predicate> InputIterator find_if( InputIterator _First, InputIterator _Last, Predicate _Pred );
find와 비교하면 첫 번째와 두 번째 파라미터는 동일합니다. 세 번째 파라미터가 다릅니다. find는 세 번째 파라미터에 찾기 원하는 값을 넘기지만 find_if는 조건자를 넘깁니다.
find_if 사용법
// 컨테이너에 저장할 유저 정의형
struct User
{
…….
int Money;
int MobKillCount;
……
};
// 조건자
struct FindBestUser()
{
…………………….
};
vector< User > Users;
……..
find_if( Users.begin(), Users.end(), FindBestUser() );
조건자가 있다는 것 이외에는 find_if는 find와 같으므로 조건자 부분만 잘 보시면 됩니다.
< 리스트 2. 특정 돈을 가지고 있는 유저 찾기 >
#include <algorithm>
#include <vector>
#include <iostream>
using namespace std;
struct User
{
int Money;
int Level;
};
struct FindMoneyUser
{
bool operator() ( User& user ) const { return user.Money == ComparMoney; }
int ComparMoney;
};
int main()
{
vector< User > Users;
User user1; user1.Level = 10; user1.Money = 2000;
User user2; user2.Level = 5; user2.Money = -10;
User user3; user3.Level = 20; user3.Money = 35000;
Users.push_back( user1 );
Users.push_back( user2 );
Users.push_back( user3 );
vector< User >::iterator FindUser;
FindMoneyUser tFindMoneyUser;
tFindMoneyUser.ComparMoney = 2000;
FindUser = find_if( Users.begin(), Users.end(), tFindMoneyUser );
if( FindUser != Users.end() )
{
cout << "소지하고 있는 돈은: " << FindUser->Money << "입니다" << endl;
}
else
{
cout << " 유저가 없습니다. " << endl;
}
return 0;
}
< 결과 > 
<리스트 2>에서는 조건자 함수를 함수 포인터가 아닌 함수 객체를 사용하였습니다. 함수 객체를 사용한 이유는 함수 객체는 inline화 되므로 함수 포인터와 비교하면 함수 포인터 참조와 함수 호출에 따른 작업이 필요 없으며, 함수 객체를 사용하면 객체에 특정 데이터를 저장할 수 있어서 조건자가 유연해집니다.
<리스트 2>의 FindMoneyUser를 일반 함수로 만들었다면 비교로 사용할 ComparMoney의 값은 함수를 정의할 때 고정됩니다. 그러나 함수 객체로 만들면 객체를 생성할 때 ComparMoney의 값을 설정할 수 있어서 유연해집니다.
<참고>
조건자를 사용하는 알고리즘 : STL의 알고리즘은 조건자를 사용하지 않는 것과 조건자를 사용하는 알고리즘 두 가지 버전을 가지고 있는 알고리즘이 있습니다. 이중 조건자를 사용하는 알고리즘은 보통 조건자를 사용하지 않는 알고리즘의 이름에서 뒤에 '_if'를 붙인 이름으로 되어 있습니다.
9.3.3. for_each
for_each는 순차적으로 컨테이너들에 담긴 데이터를 함수의 파라미터로 넘겨서 함수를 실행시키는 알고리즘입니다.
온라인 게임에서 예를 들면 플레이하고 있는 유저 객체를 vector 컨테이너인 Users에 저장하고 모든 유저들의 현재 플레이 시간을 갱신하는 기능을 구현한다면 플레이 시간을 계산하는 함수 객체 UpdatePlayTime을 만든 후 for_each에 Users의 시작과 끝 반복자와 UpdatePlayTime 함수 객체를 넘깁니다.
for_each 원형
template<class InputIterator, class Function> Function for_each( InputIterator _First, InputIterator _Last, Function _Func );
첫 번째 파라미터는 함수의 파라미터로 넘길 시작 위치, 두 번째 파라미터는 함수의 인자로 넘길마지막 위치, 세 번째는 컨테이너의 데이터를 파라미터로 받을 함수입니다.
for_each 사용 방법
// 함수 객체
struct UpdatePlayTime
{
……….
};
vector< User > Users;
for_each( Users.begin(), Users.end(), UpdatePlayTime );
아래는 위에서 예를 들었던 것을 완전한 코드로 구현한 예제 코드입니다.
< 리스트 3. for_each를 사용하여 유저들의 플레이 시간 갱신 >
#include <algorithm>
#include <vector>
#include <iostream>
using namespace std;
struct User
{
int UID;
int PlayTime;
};
struct UpdatePlayTime
{
void operator() ( User& user )
{
user.PlayTime += PlayTime;
}
int PlayTime;
};
int main()
{
vector< User > Users;
User user1; user1.UID = 1; user1.PlayTime = 40000;
User user2; user2.UID = 2; user2.PlayTime = 0;
User user3; user3.UID = 3; user3.PlayTime = 25000;
Users.push_back( user1 );
Users.push_back( user2 );
Users.push_back( user3 );
// 현재 플레이 시간
vector< User >::iterator IterUser;
for( IterUser = Users.begin(); IterUser != Users.end(); ++IterUser )
{
cout << "UID : " << cout << IterUser->UID << "의 총 플레이 시간: " << IterUser->PlayTime << endl;
}
cout << endl;
UpdatePlayTime updatePlayTime;
updatePlayTime.PlayTime = 200;
// 두 번째 유저부터 갱신
for_each( Users.begin() + 1, Users.end(), updatePlayTime );
for( IterUser = Users.begin(); IterUser != Users.end(); ++IterUser )
{
cout << "UID : " << cout << IterUser->UID << "의 총 플레이 시간: " << IterUser->PlayTime << endl;
}
return 0;
}
< 결과 > 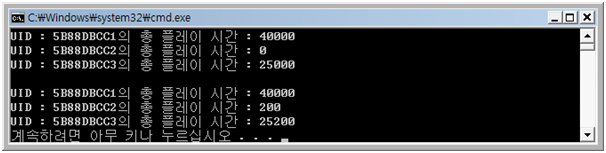
변경 불가 시킨스 알고리즘에는 위에 설명한 find, find_if, for_each 이외에 count, search, equal, adjacent_find, equal 등이 있습니다.
9.4. 변경 가능 시퀀스 알고리즘
9.3의 알고리즘들이 대상이 되는 컨테이너에 저장한 데이터를 변경하지 않는 것들이라면 이번에 설명한 알고리즘들은 제목대로 대상이 되는 컨테이너의 내용을 변경하는 알고리즘들입니다. 컨테이너에 복사, 삭제, 대체 등을 할 때는 이번에 소개할 알고리즘들을 사용합니다.
9.4.1. generate
컨테이너의 특정 구간을 특정 값으로 채우고 싶을 때가 있습니다. 이 값이 동일한 것이라면 컨테이너의 assign() 멤버를 사용하면 되지만 동일한 값이 아니라면 assign()을 사용할 수 있습니다.
이 때 사용하는 알고리즘이 generate입니다. generate 알고리즘에 값을 채울 컨테이너의 시작과 끝, 값을 생성할 함수를 파라미터로 넘깁니다.
generate 원형
template<class ForwardIterator, class Generator> void generate( ForwardIterator _First, ForwardIterator _Last, Generator _Gen );
첫 번째 파라미터는 값을 채울 컨테이너의 시작 위치의 반복자, 두 번째는 컨테이너의 마지막 위치의 반복자, 세 번째는 값을 생성할 함수 입니다.
generate 사용 방법
// 값 생성 함수
struct SetUserInfo
{
…….
};
vector< User > Users(5);
generate( Users.begin(), Users.end(), SetUserInfo() );
generate 알고리즘의 대상이 되는 컨테이너는 값을 채울 공간이 미리 만들어져 있어야 합니다. 즉 generate는 컨테이너에 데이터를 추가하는 것이 아니고 기존의 데이터를 다른 값으로 변경하는 것입니다.
< 리스트 4. generate를 사용하여 유저의 기초 데이터 설정>
struct User
{
int UID;
int RaceType;
int Sex;
int Money;
};
struct SetUserInfo
{
SetUserInfo() { UserCount = 0; }
User operator() ()
{
User user;
++UserCount;
user.UID = UserCount;
user.Money = 2000;
if( 0 == (UserCount%2) )
{
user.RaceType = 1;
user.Sex = 1;
user.Money += 1000;
}
else
{
user.RaceType = 0;
user.Sex = 0;
}
return user;
}
int UserCount;
};
int main()
{
vector< User > Users(5);
generate( Users.begin(), Users.end(), SetUserInfo() );
char szUserInfo[256] = {0,};
vector< User >::iterator IterUser;
for( IterUser = Users.begin(); IterUser != Users.end(); ++IterUser )
{
sprintf( szUserInfo, "UID %d, RaceType : %d, Sex : %d, Money : %d",
IterUser->UID, IterUser->RaceType, IterUser->Sex, IterUser->Money );
cout << szUserInfo << endl;
}
return 0;
}
< 결과 > 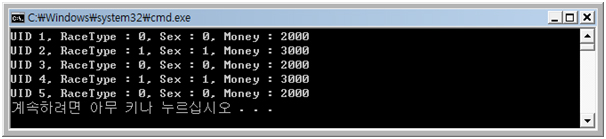
9.4.2. copy
copy 알고리즘은 컨테이너에 저장한 것과 같은 자료 형을 저장하는 다른 컨테이너에 복사하고 싶을 때 사용합니다.
컨테이너 A의 데이터를 컨테이너 B에 copy 하는 경우 컨테이너 B에 데이터를 추가하는 것이 아니고 덧쓰는 것이므로 A에서 10개를 복사하는 경우 B에는 10개만큼의 공간이 없다면 버그가 발생합니다. 또 A와 B 컨테이너는 같은 컨테이너 필요는 없습니다만 당연히 컨테이너에 저장하는 자료 형은 같아야 합니다.
copy 원형
template<class InputIterator, class OutputIterator>
OutputIterator copy(
InputIterator _First,
InputIterator _Last,
OutputIterator _DestBeg
);
copy 사용 방법
vector<int> vec1; …….. vector<int> vec2; copy( vec1.begin(), vec1.end(), vec2.begin() );
< 리스트 5. copy 알골리즘 사용 예>
#include <algorithm>
#include <vector>
#include <list>
#include <iostream>
using namespace std;
int main()
{
vector<int> vec1(10);
generate( vec1.begin(), vec1.end(), rand );
cout << "vec1의 모든 데이터를 vec2에 copy" << endl;
vector<int> vec2(10);
copy( vec1.begin(), vec1.end(), vec2.begin() );
for( vector<int>::iterator IterPos = vec2.begin();
IterPos != vec2.end();
++IterPos )
{
cout << *IterPos << endl;
}
cout << endl;
cout << "vec1의 모든 데이터를 list1에 copy" << endl;
list<int> list1(10);
copy( vec1.begin(), vec1.end(), list1.begin() );
for( list<int>::iterator IterPos2 = list1.begin();
IterPos2 != list1.end();
++IterPos2 )
{
cout << *IterPos2 << endl;
}
return 0;
}
< 결과 > 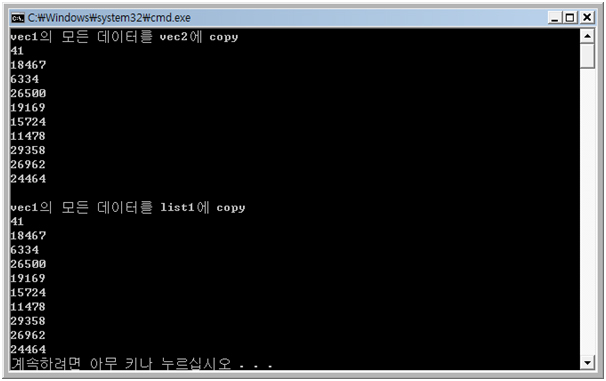
9.4.4. remove
remove 알고리즘은 컨테이너에 있는 특정 값들을 삭제하고 싶은 때 사용합니다.
주의해야 될 점은 삭제 후 크기가 변하지 않는다는 것입니다. 삭제가 성공하면 삭제 대상이 아닌 데이터들을 앞으로 몰아 넣고 마지막 위치의(컨테이너의 end()가 아닌 삭제 후 빈 공간에 다른 데이터를 쓰기 시작한 위치) 반복자를 반환합니다. 리턴 값이 가리키는 부분부터 끝(end()) 사이의 데이터 순서는 정의되어 있지 않으면 진짜 삭제를 하기 위해서는 erase()를 사용해야 합니다.
remove 원형
template<class ForwardIterator, class Type> ForwardIterator remove( ForwardIterator _First, ForwardIterator _Last, const Type& _Val );
첫 번째 파라미터는 삭제 대상을 찾기 시작할 위치의 반복자, 두 번째 파라미터는 삭제 대상을 찾을 마지막 위치의 반복자, 세 번째 파라미터는 삭제를 할 값입니다.
remove 사용 방법
vector<int> vec1; ….. remove( vec1.begin(), vec1.end(), 20 );
< 리스트 6. remove 사용 예>
#include <algorithm>
#include <vector>
#include <list>
#include <iostream>
using namespace std;
int main()
{
vector<int> vec1;
vec1.push_back(10); vec1.push_back(20); vec1.push_back(20);
vec1.push_back(40); vec1.push_back(50); vec1.push_back(30);
vector<int>::iterator iterPos;
cout << "vec1에 있는 모든 데이터 출력" << endl;
for( iterPos = vec1.begin(); iterPos != vec1.end(); ++iterPos )
{
cout << *iterPos << " " << endl;
}
cout << endl;
cout << "vec1에서 20 remove" << endl;
vector<int>::iterator RemovePos = remove( vec1.begin(), vec1.end(), 20 );
for( iterPos = vec1.begin(); iterPos != vec1.end(); ++iterPos )
{
cout << *iterPos << " " << endl;
}
cout << endl;
cout << "vec1에서 20 remove 이후 사용 하지않는 영역 완전 제거" << endl;
while( RemovePos != vec1.end() )
{
RemovePos = vec1.erase( RemovePos );
}
for( iterPos = vec1.begin(); iterPos != vec1.end(); ++iterPos )
{
cout << *iterPos << " " << endl;
}
}
< 결과 > 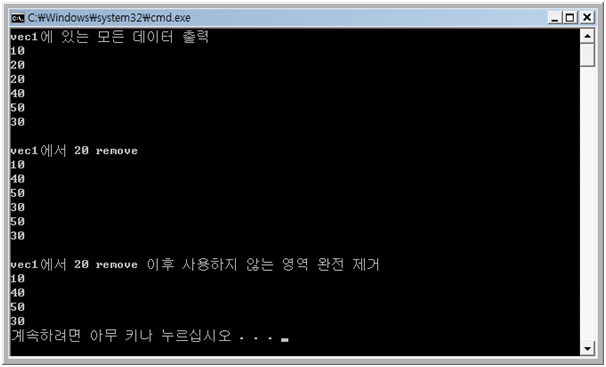
<리스트 6>에서는 remove 후 erase()로 완전하게 제거하는 예를 나타내고 있습니다.
vector<int>::iterator RemovePos = remove( vec1.begin(), vec1.end(), 20 );
로 삭제 후 남은 영역의 반복자 위치를 받은 후
while( RemovePos != vec1.end() )
{
RemovePos = vec1.erase( RemovePos );
}
로 완전하게 제거하고 있습니다.
9.4.5. replace
컨테이너의 특정 값을 다른 값으로 바꾸고 싶을 때는 replace 알고리즘을 사용합니다.
replace 원형
template<class ForwardIterator, class Type>
void replace(
ForwardIterator _First,
ForwardIterator _Last,
const Type& _OldVal,
const Type& _NewVal
);
replace 사용 방법
vector<int> vec1; …… replace( vec1.begin(), vec1.end(), 20, 30 );
< 리스트 7. replace 사용 예>
#include <algorithm>
#include <vector>
#include <list>
#include <iostream>
using namespace std;
int main()
{
vector<int> vec1;
vec1.push_back(10); vec1.push_back(20); vec1.push_back(20);
vec1.push_back(40); vec1.push_back(50); vec1.push_back(30);
vector<int>::iterator iterPos;
cout << "vec1에 있는 모든 데이터 출력" << endl;
for( iterPos = vec1.begin(); iterPos != vec1.end(); ++iterPos )
{
cout << *iterPos << " " << endl;
}
cout << endl;
cout << "vec1의 세 번째 요소부터 20을 200으로 변경" << endl;
replace( vec1.begin() + 2, vec1.end(), 20, 200 );
for( iterPos = vec1.begin(); iterPos != vec1.end(); ++iterPos )
{
cout << *iterPos << " " << endl;
}
return 0;
}
< 결과 > 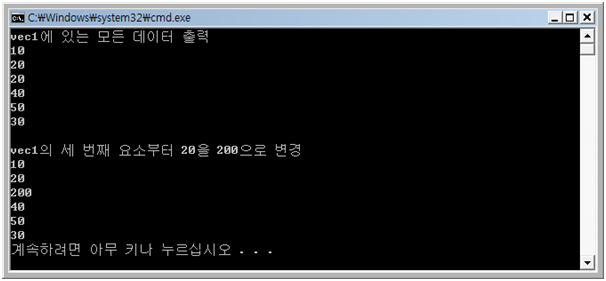
변경 가능 시퀀스 알고리즘에는 generate, copy, remove, replace 이외에도 fill, swap, reverse, transform 등이 있으니 제가 설명하지 않은 알고리즘들은 다음에 여유가 있을 때 공부하시기를 바랍니다.
지금까지 설명한 알고리즘을 보면 어떤 규칙이 있다는 것을 알 수 있을 것입니다. 알고리즘에 넘기는 파라미터는 알고리즘을 적용할 컨테이너의 위치를 가리키는 반복자와 특정 값 or 조건자를 파라미터로 넘기고 있습니다. 그래서 각 알고리즘은 이름과 기능이 다를 뿐 사용 방법은 대체로 비슷합니다. 즉 사용 방법에 일괄성이 있습니다. 그래서 하나의 알고리즘만 사용할 줄 알게 되면 나머지 알고리즘은 쉽게 사용하는 방법을 배웁니다. 이런 것이 바로 STL의 장점이겠죠
10.1. 정렬 관련 알고리즘
10.1.1 sort
sort는 컨테이너에 있는 데이터들을 내림차순 또는 오름차순으로 정렬 할 때 가장 자주 사용하는 알고리즘입니다. 컨테이너에 저장하는 데이터의 자료 형이 기본형이라면 STL에 있는 greate나 less 비교 조건자를 사용합니다(STL의 string의 정렬에도 사용할 수 있습니다. 다만 이 때는 알파벳 순서로 정렬합니다). 기본형이 아닌 경우에는 직접 비교 조건자를 만들어서 사용해야 합니다.
sort의 원형
template<class RandomAccessIterator> void sort( RandomAccessIterator _First, RandomAccessIterator _Last );
첫 번째와 두 번째 파라미터는 정렬하려는 구간의 시작과 마지막을 가리키는 반복자입니다. 비교 조건자를 필요로 하지 않고 기본형을 저장한 컨테이너를 오름차순으로 정렬합니다.
template<class RandomAccessIterator, class Pr> void sort( RandomAccessIterator _First, RandomAccessIterator _Last, BinaryPredicate _Comp );
첫 번째와 두 번째 파라미터는 정렬하려는 구간의 시작과 마지막을 가리키는 반복자입니다. 세 번째 파라미터는 정렬 방법을 기술한 비교 조건자입니다.
sort 알고리즘의 원형을 보면 알 수 있듯이 램덤 접근 반복자를 지원하는 컨테이너만 sort 알고리즘을 사용할 수 있습니다.
sort 사용 방법
vector<int> vec1; ….. // 오름차순 정렬 sort( vec1.begin(), vec1.end() ); // 내림차순 정렬 Sort( vec1.begin(), vec1.end(), greater<int>() );
< 리스트 1. less와 greater 비교 조건자를 사용한 sort >
#include <vector>
#include <iostream>
#include <algorithm>
#include <functional>
using namespace std;
int main()
{
vector<int> vec1(10);
vector<int> vec2(10);
vector<int> vec3(10);
vector <int>::iterator Iter1;
generate( vec1.begin(), vec1.end(), rand );
generate( vec2.begin(), vec2.end(), rand );
generate( vec3.begin(), vec3.end(), rand );
// 오름차순 정렬
cout << "vec1 정렬 하기 전" << endl;
for( Iter1 = vec1.begin(); Iter1 != vec1.end(); ++Iter1 ) {
cout << *Iter1 << ", ";
}
cout << endl;
sort( vec1.begin(), vec1.end() );
cout << "vec1 오름차순 정렬" << endl;
for( Iter1 = vec1.begin(); Iter1 != vec1.end(); ++Iter1 ) {
cout << *Iter1 << ", ";
}
cout << endl;
cout << endl;
// 내림차순 정렬
cout << "vec2 정렬 하기 전" << endl;
for( Iter1 = vec2.begin(); Iter1 != vec2.end(); ++Iter1 ) {
cout << *Iter1 << ", ";
}
cout << endl;
sort( vec2.begin(), vec2.end(), greater<int>() );
cout << "vec2 내림차순 정렬" << endl;
for( Iter1 = vec2.begin(); Iter1 != vec2.end(); ++Iter1 ) {
cout << *Iter1 << ", ";
}
cout << endl;
cout << endl;
// 일부만 내림차순 정렬
cout << "vec3 정렬 하기 전" << endl;
for( Iter1 = vec3.begin(); Iter1 != vec3.end(); ++Iter1 ) {
cout << *Iter1 << ", ";
}
cout << endl;
sort( vec3.begin() + 5, vec3.end(), greater<int>() );
cout << "vec3 일부만 내림차순 정렬" << endl;
for( Iter1 = vec3.begin(); Iter1 != vec3.end(); ++Iter1 ) {
cout << *Iter1 << ", ";
}
cout << endl;
return 0;
}
< 결과 > 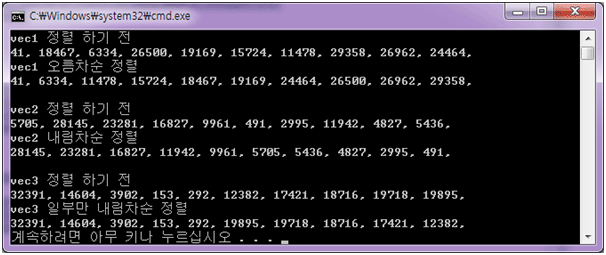
<리스트 1>은 기본 형 데이터를 정렬하는 예제로 이번에는 유저 정의 형 데이터를 정렬하는 예제를 보여 드리겠습니다.
< 리스트 2. USER 구조체의 Money를 기준으로 정렬 >
#include <vector>
#include <iostream>
#include <algorithm>
#include <functional>
using namespace std;
struct USER
{
int UID;
int Level;
int Money;
};
struct USER_MONEY_COMP
{
bool operator()(onst USER& user1, const USER& user2)
{
return user1.Money > user2.Money;
}
};
int main()
{
USER User1; User1.UID = 1; User1.Money = 2000;
USER User2; User2.UID = 2; User2.Money = 2050;
USER User3; User3.UID = 3; User3.Money = 2200;
USER User4; User4.UID = 4; User4.Money = 1000;
USER User5; User5.UID = 5; User5.Money = 2030;
vector<USER> Users;
Users.push_back( User1 ); Users.push_back( User2 );
Users.push_back( User3 ); Users.push_back( User4 );
Users.push_back( User5 );
vector <USER>::iterator Iter1;
cout << "돈을 기준으로 정렬 하기 전" << endl;
for( Iter1 = Users.begin(); Iter1 != Users.end(); ++Iter1 ) {
cout << Iter1->UID << " : " << Iter1->Money << ", ";
}
cout << endl << endl;
sort( Users.begin(), Users.end(), USER_MONEY_COMP() );
cout << "돈을 기준으로 내림차순으로 정렬" << endl;
for( Iter1 = Users.begin(); Iter1 != Users.end(); ++Iter1 ) {
cout << Iter1->UID << " : " << Iter1->Money << ", ";
}
cout << endl << endl;
return 0;
}
< 결과 > 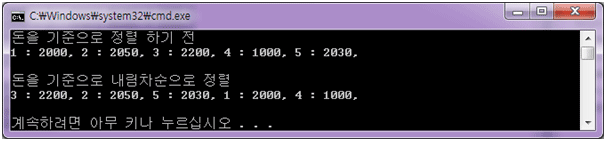
10.1.2. binary_search
이미 정렬 되어 있는 것 중에서 특정 데이터가 지정한 구간에 있는지 조사하는 알고리즘입니다. 이것도 sort와 같이 비교 조건자가 필요 없는 버전과 필요한 버전 두 개가 있습니다(단 sort와 다르게 랜덤 접근 반복자가 없는 컨테이너도 사용할 수 있습니다).
binary_search 원형
template<class ForwardIterator, class Type>
bool binary_search( ForwardIterator _First, ForwardIterator _Last, const Type& _Val );
template<class ForwardIterator, class Type, class BinaryPredicate>
bool binary_search( ForwardIterator _First, ForwardIterator _Last, const Type& _Val,
BinaryPredicate _Comp );
binary_search 사용 방법
vector<int> vec1; ….. sort( vec1.beign(), vec1.end() ); …... bool bFind = binary_search( vec1.begin(), vec1.end(), 10 );
binary_search는 정렬한 이후에 사용해야 한다고 앞서 이야기 했습니다. 만약 정렬하지 않고 사용하면 어떻게 될까요?
< 리스트 3. 정렬하지 않고 binary_search 사용 >
int main()
{
vector<int> vec1;
vec1.push_back(10); vec1.push_back(20); vec1.push_back(15);
vec1.push_back(7); vec1.push_back(100); vec1.push_back(40);
vec1.push_back(11); vec1.push_back(60); vec1.push_back(140);
bool bFind = binary_search( vec1.begin(), vec1.begin() + 5, 15 );
if( false == bFind ) {
cout << "15를 찾지 못했습니다." << endl;
} else {
cout << "15를 찾았습니다." << endl;
}
return 0;
}
디버그 모드로 빌드 후 실행 하면 아래와 같은 에러 창이 나옵니다. 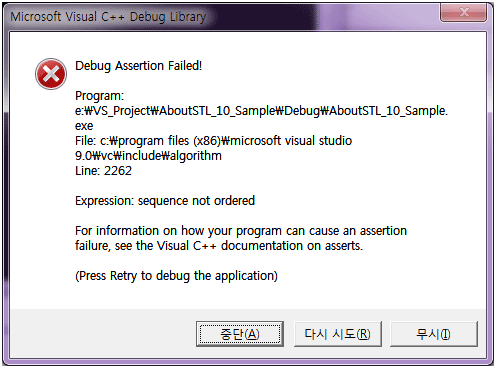
에러 내용은 시퀀스가 정렬되지 않았다고 나옵니다. 릴리즈 모드 빌드 후 실행하면 위와 같은 에러는 나오지 않지만 결과는 false가 나옵니다.
binary_search를 사용할 때는 꼭 먼저 정렬해야 한다는 것을 잊지 말기를 바랍니다.
< 리스트 4. 정렬 후 binary_search 사용 >
#include <vector>
#include <iostream>
#include <algorithm>
#include <functional>
using namespace std;
int main()
{
vector<int> vec1;
vec1.push_back(10); vec1.push_back(20); vec1.push_back(15);
vec1.push_back(7); vec1.push_back(100); vec1.push_back(40);
vec1.push_back(11); vec1.push_back(60); vec1.push_back(140);
sort( vec1.begin(), vec1.end() );
bool bFind = binary_search( vec1.begin(), vec1.begin() + 5, 15 );
if( false == bFind ) {
cout << "15를 찾지 못했습니다." << endl;
} else {
cout << "15를 찾았습니다." << endl;
}
return 0;
}
< 결과 > 
비교 조건자를 사용하는 경우는 위의 <리스트 2> 코드를 예를들면 <리스트 2>에서 사용했던 USER_MONEY_COMP 조건자를 사용합니다.
< 리스트 4. 리스트 2의 Users를 binary_search에 사용 >
……. sort( Users.begin(), Users.end(), USER_MONY_COMP() ); bool bFind = binary_search( Users.begin(), Users.begin() + 3, User5, USER_MONY_COMP() ); …….
10.1.3 merge
두 개의 정렬된 구간을 합칠 때 사용하는 것으로 두 구간과 겹치지 않은 곳에 합친 결과를 넣어야 합니다. 주의해야 할 점은 합치기 전에 이미 정렬이 되어 있어야 하며 합친 결과를 넣는 것은 합치는 것들과 겹치면 안되며, 또한 합친 결과를 넣을 수 있는 공간을 확보하고 있어야 합니다.
merge의 원형
template<class InputIterator1, class InputIterator2, class OutputIterator>
OutputIterator merge( InputIterator1 _First1, InputIterator1 _Last1,
InputIterator2 _First2, InputIterator2 _Last2, OutputIterator _Result
);
template<class InputIterator1, class InputIterator2, class OutputIterator, class BinaryPredicate>
OutputIterator merge( InputIterator1 _First1, InputIterator1 _Last1,
InputIterator2 _First2, InputIterator2 _Last2, OutputIterator _Result, BinaryPredicate _Comp );
merge 사용 방법
vector<int> vec1, vec2, vec3; ….. merge( vec1.begin(), vec1.end(), vec2.begin(), vec2.end(), vec3.begin() );
아래의 <리스트 5>는 vec1과 vec2를 합쳐서 vec3에 넣는 것으로 vec1과 vec2는 이미 정렬되어 있고 vec3는 이 vec1과 vec2의 크기만큼의 공간을 미리 확보해 놓고 있습니다.
< 리스트 5. 두 개의 vector의 merge >
#include <vector>
#include <iostream>
#include <algorithm>
#include <functional>
using namespace std;
int main()
{
vector <int>::iterator Iter1;
vector<int> vec1,vec2,vec3(12);
for( int i = 0; i < 6; ++i )
vec1.push_back( i );
for( int i = 4; i < 10; ++i )
vec2.push_back( i );
cout << "vec1에 있는 값" << endl;
for( Iter1 = vec1.begin(); Iter1 != vec1.end(); ++Iter1 ) {
cout << *Iter1 << ", ";
}
cout << endl;
cout << "vec2에 있는 값" << endl;
for( Iter1 = vec2.begin(); Iter1 != vec2.end(); ++Iter1 ) {
cout << *Iter1 << ", ";
}
cout << endl;
merge( vec1.begin(), vec1.end(),
vec2.begin(), vec2.end(),
vec3.begin() );
cout << "vec1과 vec2를 merge한 vec3에 있는 값" << endl;
for( Iter1 = vec3.begin(); Iter1 != vec3.end(); ++Iter1 ) {
cout << *Iter1 << ", ";
}
cout << endl;
return 0;
}
< 결과 > 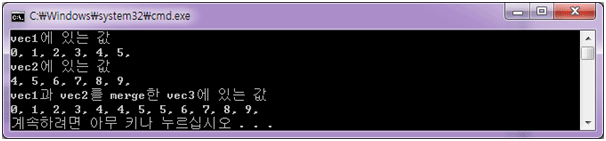
정렬 관련 알고리즘은 위에 소개한 세 개 이외에도 더 있지만 지면 관계상 보통 자주 사용하는 sort, binary_search, merge 세 개를 소개하는 것으로 마칩니다. 제가 소개하지 않은 정렬 관련 알고리즘을 더 공부하고 싶은 분들은 MSDN이나 C++ 책을 통해서 공부하시기를 바랍니다.
10.2. 범용 수치 알고리즘
10.2.1 accumulate
지정한 구간에 속한 값들을 모든 더한 값을 계산합니다. 기본적으로 더하기 연산만 하지만 조건자를 사용하면 더하기 이외의 연산도 할 수 있습니다. accumulate를 사용하기 위해서는 앞서 소개한 알고리즘과 다르게 <numeric> 헤더 파일을 포함해야 합니다.
accumulate의 원형
template<class InputIterator, class Type> Type accumulate( InputIterator _First, InputIterator _Last, Type _Val );
첫 번째와 두 번째 파라미터는 구간이며, 세 번째 파라미터는 구간에 있는 값에 더할 값입니다.
template<class InputIterator, class Type, class BinaryOperation> Type accumulate( InputIterator _First, InputIterator _Last, Type _Val, BinaryOperation _Binary_op );
네 번째 파라미터는 조건자로 조건자를 사용하여 기본 자료 형 이외의 데이터를 더할 수 있고, 더하기 연산이 아닌 다른 연산을 할 수도 있습니다.
accumulate 사용 방법
vector<int> vec1; ….. // vec1에 있는 값들만 더 한다. int Result = accmulate( vec1.begin(), vec1.end(), 0, );
아래의 <리스트 6>은 int를 저장하는 vector를 대상으로 accmurate를 사용하는 가장 일반적인 예입니다.
< 리스트 6. vector에 있는 값들을 계산 >
#include <vector>
#include <iostream>
#include <numeric>
using namespace std;
int main()
{
vector <int>::iterator Iter1;
vector<int> vec1;
for( int i = 1; i < 5; ++i )
vec1.push_back( i );
// vec1에 있는 값
for( Iter1 = vec1.begin(); Iter1 != vec1.end(); ++Iter1 ) {
cout << *Iter1 << ", ";
}
cout << endl;
// vec1에 있는 값들을 더한다.
int Result1 = accumulate( vec1.begin(), vec1.end(), 0 );
// vec1에 있는 값들을 더한 후 10을 더 한다.
int Result2 = accumulate( vec1.begin(), vec1.end(), 10 );
cout << Result1 << ", " << Result2 << endl;
}
< 결과 > 
이번에는 조건자를 사용하여 유저 정의형을 저장한 vector를 accmulate에서 사용해 보겠습니다. 이번에도 더하기 연산만을 했지만 조건자를 사용하면 곱하기 연산 등도 할 수 있습니다.
< 리스트 7. 조건자를 사용한 accumulate >
#include <vector>
#include <iostream>
#include <numeric>
using namespace std;
struct USER
{
int UID;
int Level;
int Money;
};
struct USER_MONY_ADD
{
USER operator()(const USER& user1, const USER& user2)
{
USER User;
User.Money = user1.Money + user2.Money;
return User;
}
};
int main()
{
USER User1; User1.UID = 1; User1.Money = 2000;
USER User2; User2.UID = 2; User2.Money = 2050;
USER User3; User3.UID = 3; User3.Money = 2200;
USER User4; User4.UID = 4; User4.Money = 1000;
USER User5; User5.UID = 5; User5.Money = 2030;
vector<USER> Users;
Users.push_back( User1 ); Users.push_back( User2 );
Users.push_back( User3 ); Users.push_back( User4 );
Users.push_back( User5 );
vector <USER>::iterator Iter1;
for( Iter1 = Users.begin(); Iter1 != Users.end(); ++Iter1 ) {
cout << Iter1->UID << " : " << Iter1->Money << ", ";
}
cout << endl << endl;
// Users에 있는 Money 값만 더하기 위해 Money가 0인 InitUser를 세 번째 파라미터에
// 조건자를 네 번째 파라미터로 넘겼습니다.
USER InitUser; InitUser.Money = 0;
USER Result = accumulate( Users.begin(), Users.end(), InitUser, USER_MONY_ADD() );
cout << Result.Money << endl;
}
< 결과 > 
10.2.2 inner_product
두 입력 시퀀스의 내적을 계산하는 알고리즘으로 기본적으로는 +와 *을 사용합니다. 두 입력 시퀀스의 값은 위치의 값을 서로 곱한 값을 모두 더 한 것이 최종 계산 값이 됩니다. 주의 해야 할 것은 두 입력 시퀀스의 구간 중 두 번째 시퀀스는 첫 번째 시퀀스 구간 보다 크거나 같아야 합니다. 즉 첫 번째 시퀀스 구간의 데이터는 5개가 있는데 두 번째 시퀀스에 있는 데이터가 5개 보다 작으면 안됩니다.
inner_product의 원형
template<class InputIterator1, class InputIterator2, class Type>
Type inner_product( InputIterator1 _First1, InputIterator1 _Last1, InputIterator2 _First2,
Type _Val );
조건자를 사용하는 버전으로 조건자를 사용하면 유저 정의형을 사용할 수 있는 내적 연산 방법을 바꿀 수 있습니다.
template<class InputIterator1, class InputIterator2, class Type,
class BinaryOperation1, class BinaryOperation2>
Type inner_product( InputIterator1 _First1, InputIterator1 _Last1, InputIterator2 _First2,
Type _Val, BinaryOperation1 _Binary_op1, BinaryOperation2 _Binary_op2 );
아래의 <리스트 8>은 조건자를 사용하지 않는 inner_product를 사용하는 것으로 vec1과 vec2의 내적을 계산합니다.
< 리스트 8. inner_product를 사용하여 내적 계산 >
#include <vector>
#include <iostream>
#include <numeric>
using namespace std;
int main()
{
vector<int> vec1;
for( int i = 1; i < 4; ++i )
vec1.push_back(i);
vector<int> vec2;
for( int i = 1; i < 4; ++i )
vec2.push_back(i);
int Result = inner_product( vec1.begin(), vec1.end(), vec2.begin(), 0 );
cout << Result << endl;
return 0;
}
< 결과 > 
<리스트 8>의 vec1과 vec2에는 각각 1, 2, 3 의 값이 들어가 있습니다. 이것을 네 번째 파라미터의 추가 값을 0을 넘긴 inner_droduct로 계산하면
14 = 0 + (1 * 1) + (2 * 2) + (3 * 3);
가 됩니다.
<리스트 8>의 코드를 보기 전에는 어떻게 계산 되는지 잘 이해가 되지 않는 분들은 <리스트 8> 코드를 보면 inner_product가 어떻게 계산 되는지 쉽게 이해할 수 있을 것입니다.
inner_product도 다른 알고리즘처럼 조건자를 사용할 수 있습니다. 제가 앞서 다른 알고리즘에서 조건자를 사용한 예를 보여 드렸으니 inner_product에서 조건자를 사용하는 방법은 숙제로 남겨 놓겠습니다.^^
범용 수치 알고리즘에는 위에 설명한 accmulate와 inner_product 이외에도 더 있지만 다른 것들은 보통 사용 빈도가 높지 않고 그것들을 다 소개하기에는 많은 지면이 필요로 하므로 이것으로 끝내겠습니다.^^;
범용 수치 알고리즘을 끝으로 STL의 알고리즘을 설명하는 것을 마치겠습니다. 이전 회와 이번에 걸쳐서 소개한 알고리즘은 STL에 있는 알고리즘 중 사용 빈도가 높은 알고리즘들로 이 것 이외에도 많은 알고리즘이 있으니 제가 설명한 알고리즘을 공부한 후에는 제가 설명하지 않은 알고리즘들도 공부하시기를 바랍니다.
지금까지 제가 설명한 글들을 보시면 STL은 사용할 때 일관성이 높다라는 것을 알 수 있을 것입니다. 높은 일관성 덕분에 하나를 알면 그 다음은 더 쉽게 알 수 있습니다.
C++의 STL은 결코 사용하기 어려운 것이 아닙니다. C++을 알고 있다면 아주 쉽게 공부할 수 있으며 STL을 사용함으로 더 쉽고 견고하게 프로그래밍할 수 있습니다. 그러나 STL의 컨테이너나 알고리즘에 대해서 잘 모르면서 다른 사람들이 사용한 코드를 보고 그냥 사용하면 STL이 독이 될 수도 있음을 조심해야 합니다.
저는 몇 달 전부터 C++0x을 공부하고 있습니다. C++0x는 현재 개발중인 새로운 C++ 표준입니다. C++0x에는 지금의 C++을 더 강력하고 쉽게 사용할 수 있게 해 주는 다양한 것들이 있습니다. 이 중 lambda라는 것이 있는데 이것을 사용하면 알고리즘에서 조건자를 사용할 때 지금보다 훨씬 더 편하게 기술할 수 있습니다. STL을 공부한 이 후에는 C++0x을 공부하시기를 바랍니다.